Data Storage & Memory Access
Astro 497: Week 10, Monday
TableOfContents()Logistics
Should have received Project Plan feedback via Canvas
If you/your team didn't address one or more of the plan components, then please address those as part of your checkpoint 1 (or before if it would be helpful).
Memory latency hierarchy
Registers:
Caches:
RAM
Local disk storage
Non-local disks
Tape storage (e.g., Roar Near-line storage)
Registers:
All calculations are based on data in registers
Only a few dozen registers per CPU core
Many of those are special purpose (e.g., performing multiple arithmetic operations at once)
Caches:
L1 Cache:
Very low latency
Typically 16 – 64KB data cache per core
Separate instruction cache
L2 Cache:
Typically a few times slower than L1 cache
Typically 256KB - few MB L2 cache per core (or pair of cores)
L3 Cache:
Typically ~10 times slower than L2 cache
Typically ~few to tens or even hundreds of MB
Often shared among all CPU cores
N-way associative cache → How many different places a variable could be in the cache
RAM
GB to TB
Symmetric Multiprocessing (SMP): all cores have equal access to all RAM
Non-Uniform Memory Access (NUMA):
RAM divided
Some is assigned to be "local" to each core (or pair of cores)
Rest of RAM is accessible via an interconnect
Disk storage
Local disk storage
NVME
SSD
Dard drives
Disk storage within local network
Disk storage over internet
Internet2
Commodity internet
Tape storage
Very high latency
Can still have high throughput
Efficient in terms cost, energy & reliability
On Roar, known as "near-line archival storage"
Where do your variables go?
Programmer explicitly chooses when to write to disk or access network.
(Some cloud programming frameworks abstract these away)
The vast majority of scientific software development uses high-level languages.
High-level languages let compilers and CPUs manage caches
Programmer choices can make it easy/hard/impossible for them to use caches effectively.
Programmer choices also dictate whether variables are stored in:
Stack (scalars, small structures or collections with known size)
Heap (large collections, structures/collections with unknown size)
Stack
 (from Wikimedia)
(from Wikimedia)
Stack memory is released on a last-in-first-out basis.
Stack (de)allocation is much faster than allocation/deallocation from heap.
Stack has fixed size (e.g., 8MB is default on linux, can change with
ulimit -s)Active frame of stack is likely to stay in cache
Stack is good for variables:
Whose size is known at compile time,
Aren't too large
Won't be needed after a function finishes
Use heap for
Large collections (e.g., arrays, matrices) that are stored contiguously in memory.
Collections whose size is unknown at compile time
Collections vary in size (in hard to predict way)
Key factors for achieving good performance
From highest to lowest priority:
Choose an appropriate algorithm for your problem
Use compiled language, rather than an interpreted language
Use variables with fixed and known types
Minimize[1] disk/network/tape access
Minimize[1] unnecessary memory allocations on heap
Choose data types that promote linear access, e.g.,
Vectors & Arrays (rather than Dictionaries)
Arrays of values (rather than arrays of pointers)7. Group reads/writes of nearby data
For matrices, inner loop over minor dimension
For large matrices, there are clever strategies of working on smaller blocks at a time. Use cache-optimized libraries, e.g.,
BLAS, LAPACK, IntelMKL
For datasets with many columns, structures of arrays (rather than arrays of structures)
Use programming patterns that make it easy to parallelize the "embarrassingly parallel" portions of your code.
E.g.,
map,mapreduce,split-apply-combineOnce fully tested in serial, then can turn on parallelism for those sections easily.
Only after ensuring that you've done all of the above, should you even consider using "advanced" programming techniques that obfuscate the code, make it hard to maintain, or are likely to soon become out-of-date.
1
Use it when you need it, but don't add lots of extra small read/writes to disk or memory allocations.
2
By default. With Julia & Numby, one can explicitly specify a variable to be stored in the opposite format.
What is not on the list for achieving high performance?
"Vectorization" The word vectorization is used in two fundamentally different ways:
Computing hardware, e.g.
SSE, SSE2, AVX, AVX512
GPU Streamming Multiprocessors
Programming patterns, e.g.,
z = x + y
In many places, vectorization, as in the programming pattern, can make code easier to read. However, often it results in unnecessary memory allocations and cache misses[3]. Therefore, be careful about using vectorized notation in performance-sensitive sections of code.
3
In many cases, Julia and JAX can broadcast and fuse vectorized expressions to achieve nearly identical performance as hand-written loops.
Compiled vs Interpretted Languages
Q: When optimizing Python [or R, IDL,...] code I've been told to eliminate for loops wherever possible. For Julia (or C/C++, Fortran, Java,...) for loops are not detrimental. Why is this?
Interpretted languages:
Loops are very slow
Usually worth creating extra arrays to avoid explicit loops
Compiled languages:
Loops are fast.
Usually choose whether to write loop explicilty based on what's more convenient for programmer.
Using "vectorized" notation can add unnecessary memory allocations and cache misses...
if you don't use broadcasting and fusing


{kind=link}
Why are computers becoming more parallel?
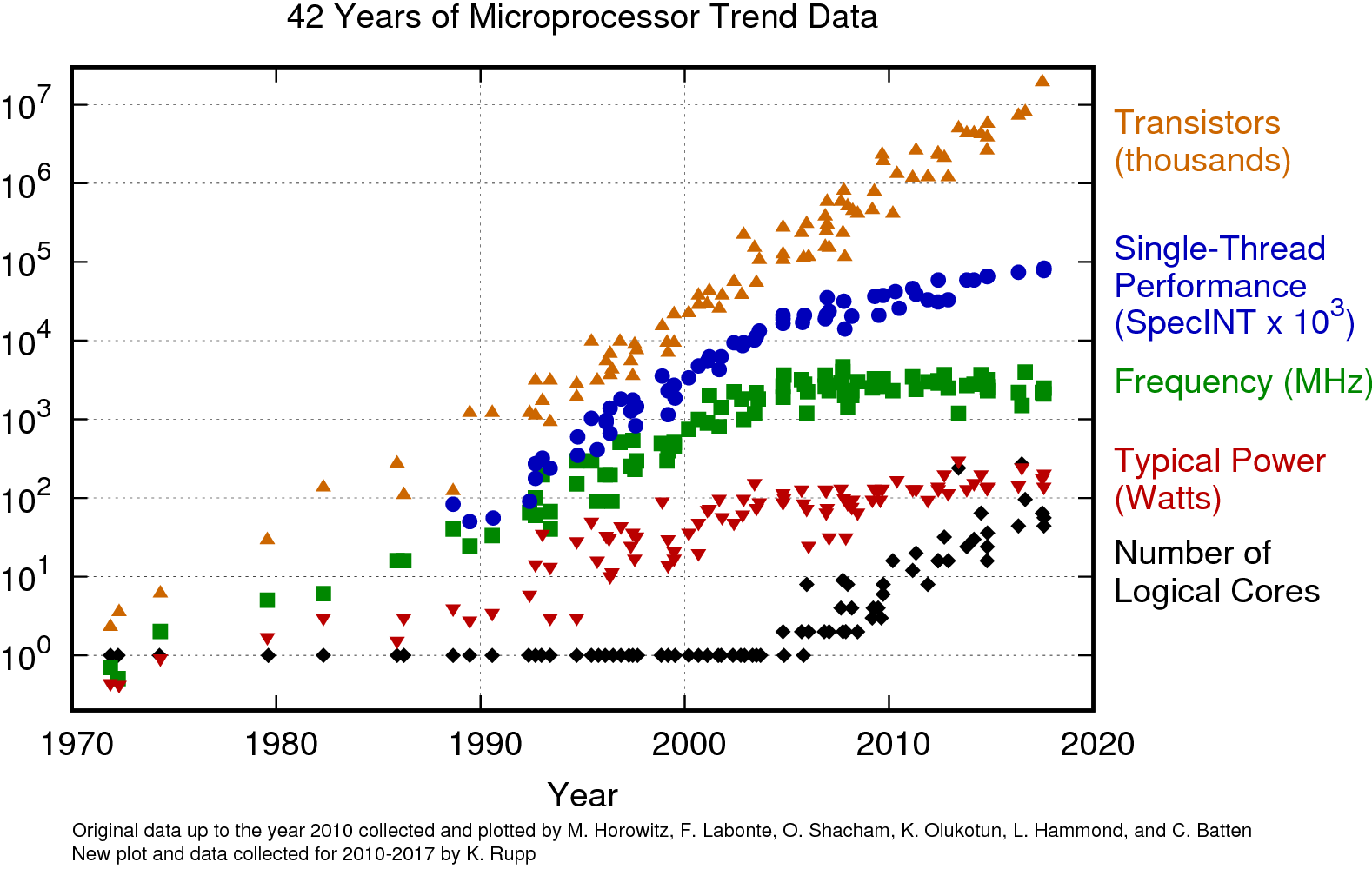 - source: K. Rupp blog
- source: K. Rupp blog
Data structures
Array
Good when:
Value fast access to individual elements, even if not in linear order
But even faster if elements will often be accessed in linear order
Know how many elements you'll need (or at least can make a decent guess)
Don't want to allocate more memory that you actually need
There's not a reason to use a more complicated data structure
Hash table (aka dictionary/Dict)
Good when:
Elements unlikely to be accessed in any particular order
Value pretty fast access to individual elements
Don't mind allocating significantly more memory than necessary
Useful for scripting, non-performance sensitive code
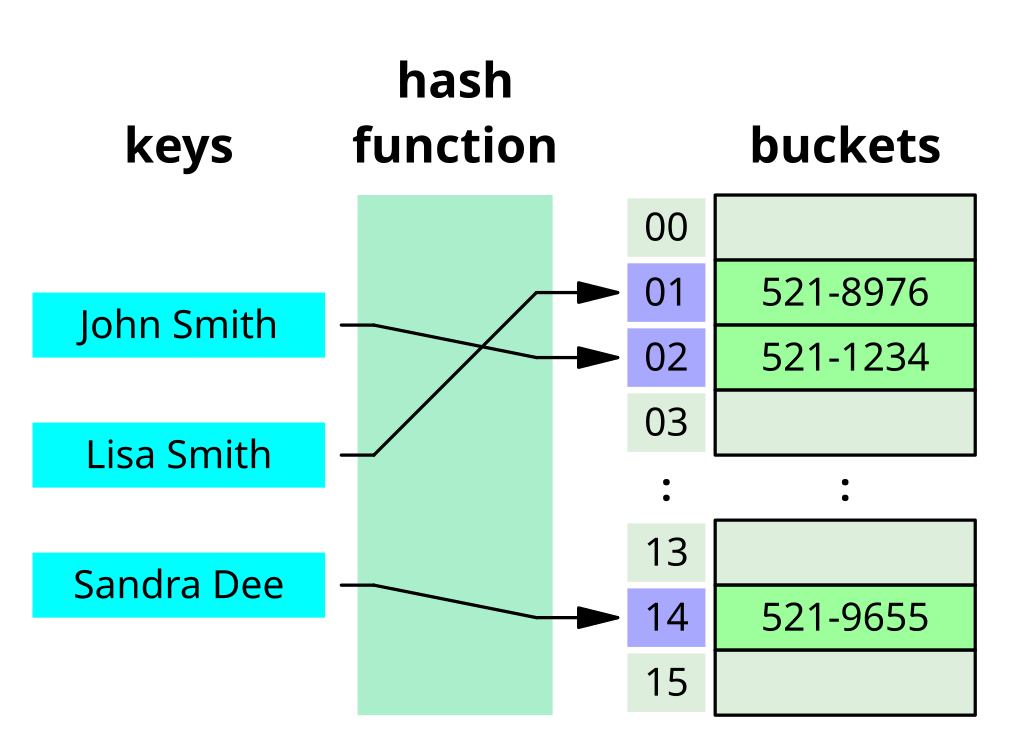 - source Wikimedia, Jorge Stolfi, CC-BY-SA-3.0
- source Wikimedia, Jorge Stolfi, CC-BY-SA-3.0
{kind=link}
Some form of tree when:
Elements have a meaningful order
Value fast adding/removing and searching of elements
Value not allocating (much) more memory than necessary
Don't mind taking longer to access individual elements
Willing to spend some time maintaining well-ordered tree
Common in database applications
Generic tree (not particularly useful)
 - source Wikimedia
- source Wikimedia
{kind=link}
Balanced binary tree
 - source Wikimedia
- source Wikimedia
{kind=link}
Linked List

Use array when:
Know size at time of creation (or won't need to change size often)
Value fast access to elements (not just the beginning/end)
Value not allocating more memory than memory
Very common for scientific performance sensitive code
Use linked list when:
Likely to insert elements and/or change size often
Don't mind taking longer to access elements (other than beginning/end)
Value not allocating (much) more memory than necessary
Useful for frequent sorting
Other common data structures to consider...
Garbage Collection
Julia's garbage collector is "a non-compacting, generational, mark-and-sweep, tracing collector, which at a high level means the following…
Mark-Sweep / Tracing:
When the garbage collector runs, it starts from a set of “roots” and walks through the object graph, “marking” objects as reachable.
Any object that isn’t marked as reachable and will then be “swept away” — i.e. its memory is reclaimed—since you know it’s not reachable from the roots and is therefore garbage.
Generational:
It’s common that more recently allocated objects become garbage more quickly—this is known as the “generational hypothesis”.
Generational collectors have different levels of collection: young collections which run more frequently and full collections which run less frequently.
If the generational hypothesis is true, this saves time since it’s a waste of time to keep checking if older objects are garbage when they’re probably not."
Non-compacting / Non-moving:
Other garbage collection techniques can copy or move objects during the collection process.
Julia does not use any of these—collection does not move or copy anything, it just reclaims unreachable objects.
If you’re having issues with garbage collection, your primary recourse is to generate less garbage:
Write non-allocating code wherever possible: simple scalar code can generally avoid allocations.
Use immutable objects (i.e.,
structrather thanmutable struct), which can be stack allocated more easily and stored inline in other structures (as compared to mutable objects which generally need to be heap-allocated and stored indirectly by pointer, all of which causes more memory pressure).Use pre-allocated data structures and modify them instead of allocating and returning new objects, especially in loops.
Can call
GC.gc()to manually call garbage collector. But this is mainly useful for benchmarking.
(nearly quote from Julia Discourse post by Stefan Karpinski)
Setup & Helper Code
ChooseDisplayMode()using PlutoUI, PlutoTeachingToolsBuilt with Julia 1.8.2 and
PlutoTeachingTools 0.2.3PlutoUI 0.7.44
To run this tutorial locally, download this file and open it with Pluto.jl.
To run this tutorial locally, download this file and open it with Pluto.jl.
To run this tutorial locally, download this file and open it with Pluto.jl.
To run this tutorial locally, download this file and open it with Pluto.jl.